Student guides
Turnitin Risk Management for Hybrid AI + Human Workflows
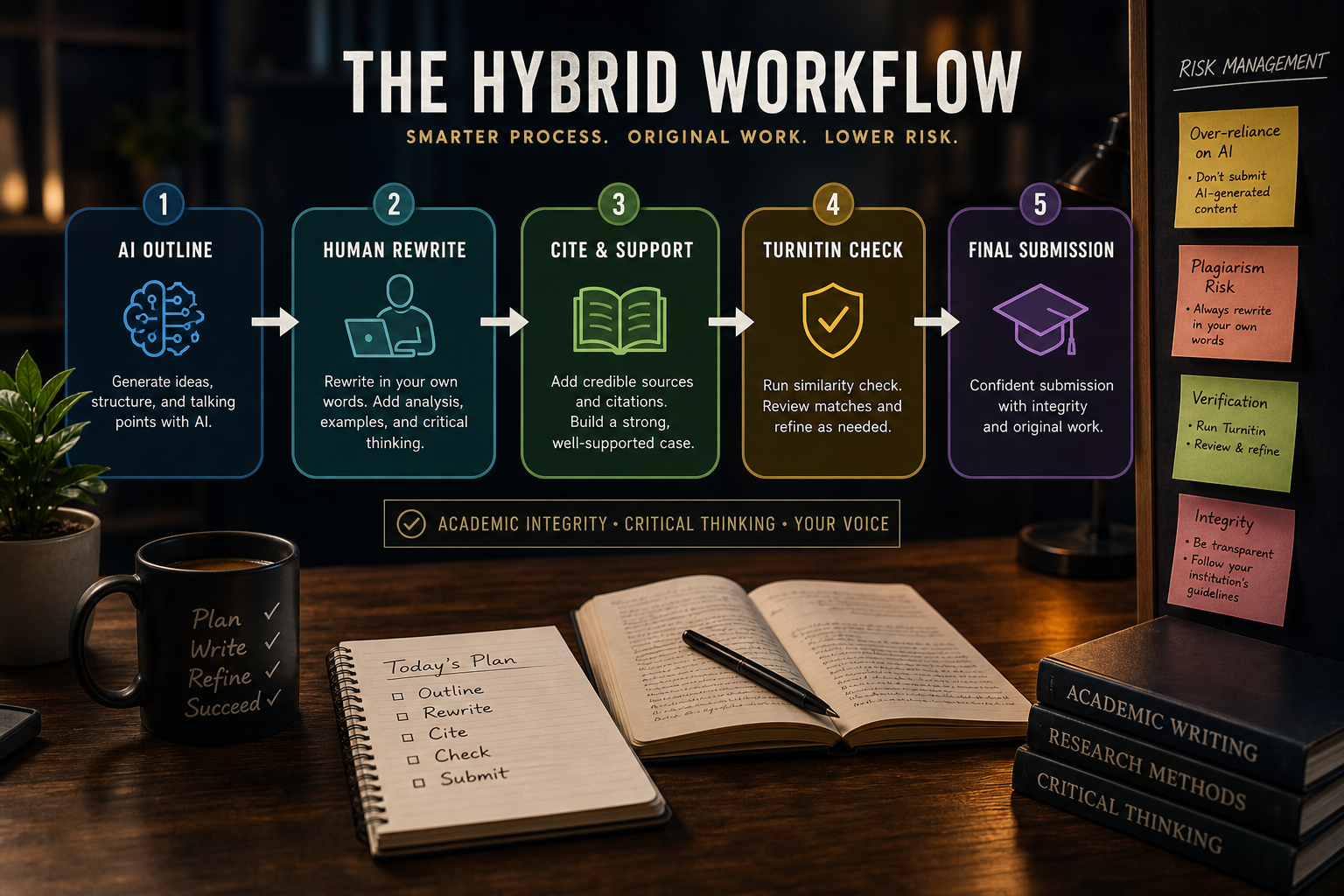
Hybrid drafts need hybrid QA. Plan detector risk the way you plan citations — before the final hour.
Updated June 2026
What detectors actually measure
Turnitin and similar tools do not grade your thinking — they score patterns. Similarity reports flag overlapping strings against published text, prior student submissions, and institutional repositories. AI-writing indicators, where enabled, look for statistical regularities associated with machine-generated prose: uniform sentence length, low perplexity, predictable transitions. Neither tool knows whether you understood the material. Both can produce false positives and false negatives that students treat as verdicts when they are really probabilistic guesses dressed in traffic-light colors. Learning what each channel measures is the first step toward managing hybrid drafts instead of fearing upload day. Ask your TA which report channel your course actually uses before you optimize the wrong dashboard color.
The practical mistake is assuming a green similarity badge means you are safe. A paper can show twelve percent overlap — all properly quoted — while still triggering an AI flag because the unquoted prose reads like a model. Conversely, a heavily human-edited draft may show higher similarity if your writer recycled phrasing from a prior client paper in the same subject. Detectors measure surface signals, not authorship intent. Treating them as character references for your integrity is a category error that costs grades every semester when students optimize for the wrong dashboard color instead of the argument their instructor will actually read.
Campus policies differ on which signals matter. Some instructors treat AI flags as conversation starters; others treat them as automatic integrity referrals. Before you blend AI outlines with human paragraphs or vice versa, read your syllabus and any faculty guidance on generative tools. Ask your TA which report they actually open — similarity only, AI only, or both. Risk management starts with knowing the rules of the game on your specific course, not with Reddit threads about beating detectors that may not even match your institution's configuration or update schedule this term. Budget ninety minutes of rhythm edits after delivery instead of running the file through a paraphraser.
Human draft + AI outline risks
A common hybrid workflow runs like this: ChatGPT produces an outline and topic sentences; a human writer fills body paragraphs; you polish the introduction. Each handoff introduces a different fingerprint. Outlines from models tend toward symmetrical three-point structures and generic transition phrases. Human writers may import subject-specific jargon and citation habits from their own backlog. Turnitin sees a patchwork, not a single authorial voice — and patchwork is exactly what both similarity engines and AI scorers were built to notice across sections that never went through the same author's judgment or your own revision pass. Compare the draft to work you submitted last month so fluency spikes are visible before faculty notice.
The outline step is where many students over-trust AI. Models suggest sources that sound real, arguments that sound balanced, and section headers that mirror every rubric you have ever seen. If your human writer follows that outline faithfully, you inherit both the structure and its statistical signature. Worse, if the outline included paraphrased material from web snippets, similarity scores climb in sections you never personally researched. You end up defending prose you did not write and patterns you did not choose when an instructor asks why section two sounds nothing like section four in tone or evidence density.
Risk reduction here means treating the AI outline as a straw proposal, not a blueprint. Reorder sections to match your course's actual readings. Replace model-generated topic sentences with questions your professor asked in lecture. Ask your human writer to deviate from the outline where your own notes suggest a better arc. Upload your lecture slides or discussion posts as voice anchors so the human layer has something real to align with. The goal is one coherent argument path — not a clean stack of machine logic topped with human polish that still moves like a machine underneath when read aloud.
Voice editing as risk reduction
Voice editing is the step most students skip because it feels cosmetic. It is not. Read your draft aloud at conversational speed. Every phrase you would never say in office hours is a flag waiting to happen — for your instructor even before any algorithm runs. Swap abstract nouns for verbs you actually use. Break one long sentence per paragraph into two shorter ones. Insert a specific example from your lab section or discussion board. Voice work is slow, but it is the cheapest insurance against both human suspicion and detector uniformity when multiple tools touched the draft before you claimed it as yours.
Human writers can mimic tone if you give them samples — a prior essay, a discussion post, even a well-written email to your TA. Models can approximate tone but revert to mean under pressure, especially in conclusions where they default to uplift language about society or the future. After delivery, budget ninety minutes not for grammar but for voice: rewrite openings, replace stock transitions, and add one imperfect sentence that sounds like you thinking on the page. Perfection is suspicious; recognizable struggle is not, and struggle is what detectors associate with human drafting when sentence rhythm varies naturally.
Voice passes also reduce AI-detector risk because detectors partly score uniformity. Human speech is messy: minor redundancies, occasional fragments, idiosyncratic word choices. You are not trying to perform error — you are trying to break the metronome. If a paragraph could appear in any student's paper on any campus, it still needs your fingerprints before upload. Compare side by side with something you wrote last month; the family resemblance should be visible even if the polish level changed after external help. Instructors who know your discussion posts will notice fluency spikes faster than any software dashboard. Last-minute model polish on human sections often adds fresh machine signatures overnight.
Similarity vs AI flags
Similarity and AI flags are separate channels that students conflate at their peril. High similarity usually traces to quotations, bibliography overlap, common phrases in your discipline, or a writer reusing phrasing. AI flags often appear in sections with no matched source at all — the detector is guessing authorship, not copying. Fixing one does not fix the other. Running your paper through a free online AI checker before Turnitin tells you almost nothing about what your institution actually uses, because vendors tune models differently and update thresholds without announcing it to students who treat third-party scores as prophecy.
If similarity clusters in the bibliography or methods section, check whether your writer padded with generic definitions from textbooks. Trim or rewrite those blocks even when they are technically paraphrased. If AI flags concentrate in the introduction and conclusion — common model habitats — rewrite those sections entirely by hand without looking at the draft. Keep the body citations intact if they are accurate. Never run the whole essay through a paraphrasing tool to fix similarity; you will trade one flag for another and lose meaning in the process while creating a third authorship fingerprint neither channel was designed to interpret kindly.
Document your process. Screenshot your outline versions, note which sections you rewrote, keep your source PDFs organized in a folder with the same name as your final file. You may never need this evidence, but students who can show a revision trail fare better in integrity conversations than students who panic and delete files. Hybrid workflows are defensible when the human labor is real and logged, not when you toggled between tabs and hoped for the best on submission night without a single timestamped version saved locally. Patchwork voices across sections are exactly what similarity engines and AI scorers were built to detect.
Submission-week workflow
Treat submission week as a QA sprint with fixed checkpoints, not a single panic edit. Four days out: verify every citation against your library PDFs and fix broken DOIs. Three days out: run a similarity preview if your campus offers a student-side draft check, then rewrite flagged clusters. Two days out: voice pass aloud, then sleep on it. One day out: format to rubric specs and re-read only the thesis, topic sentences, and conclusion. Build the calendar backward from upload, not forward from when the writer delivers — vendor on-time and campus-ready are different finish lines with different failure costs.
Do not run experimental prompts through the finished draft the night before. Last-minute AI polish is how clean human work acquires machine signatures. If you need help that late, pay for a targeted human edit scoped to clarity — not a generator asked to improve your essay. The cheapest risk reduction is time; the most expensive is an integrity meeting you could have avoided with a calendar. Students who plan hybrid workflows without buffer days pay twice: once in rush fees, once in detector roulette when every fix introduces a new surface pattern the dashboard was not showing yesterday.
After upload, resist the urge to reopen the file unless you discover a factual error. Some LMS platforms timestamp late changes; some instructors download submissions immediately. Hybrid workflows succeed when you front-load detector risk — citations, voice, structure — and treat upload as the end of production, not the start of authorship. PaperHelp, EssayPro, and 99papers can deliver usable human drafts, but none of them upload for you. The last mile is always yours, and that is where Turnitin risk is actually managed before the grade book closes and the file becomes evidence in any later review.
Compare services with real review data
Use our match tool or read ranked reviews before you order — human writers, tracked cashback on partners, and quality index scores side by side.
Related reading
More in blog
Service reviews
Ranking guides